Frequently Asked Questions
How do I skip a step?
You might want to use a template but without one of its steps.
To do this, replace the unwanted step with any shell command that returns a successful status, such as echo, true, or even just :. Commands must be strings, so commands such as true or : should be quoted. Commands with backticks must be quoted too. Commands that return an unsuccessful status will abort the build.
Partial example:
steps:
- first: echo I am skipping step first
- second: 'true'
- third: ":"
- WRONG: "`exit 22`"
How do I skip a build?
You might want to skip a build if you’re only changing documentation.
If you don’t want Screwdriver to trigger a build when you’re pushing to your base branch, add [ci skip] or [skip ci] to the commit message on any of the commits off the pull request.
Note: Doesn’t apply to pull request builds: a commit message containing [skip ci] or [ci skip] will still trigger a pre-commit job (a PR job will always run).
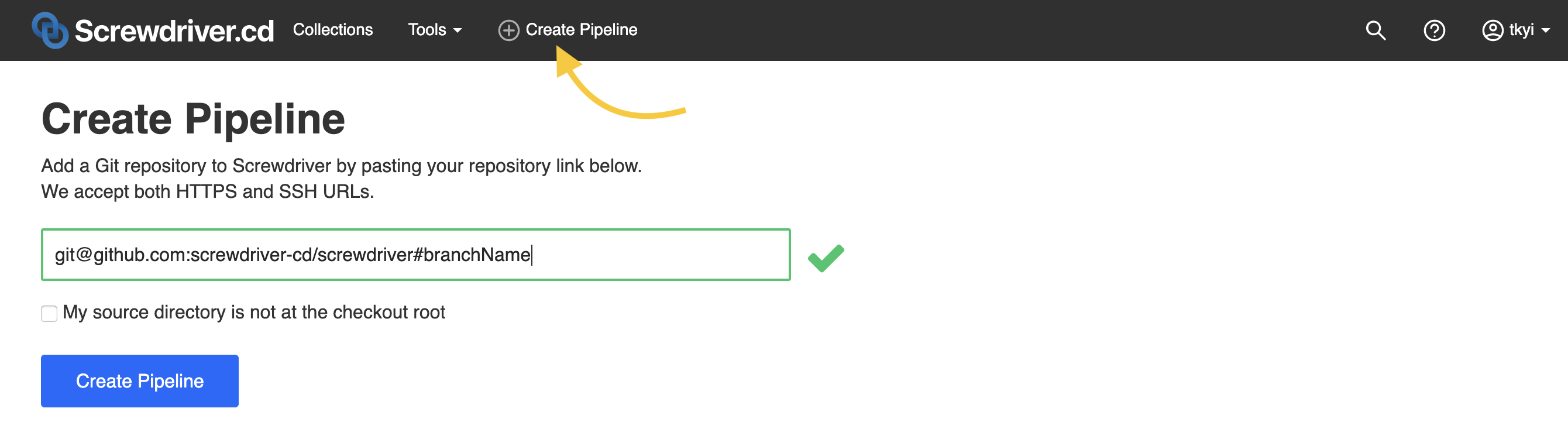
How do I create a pipeline?
To create a pipeline, click the Create icon and paste a Git URL into the form. Followed by # and the branch name, otherwise SCM default branch will be used.
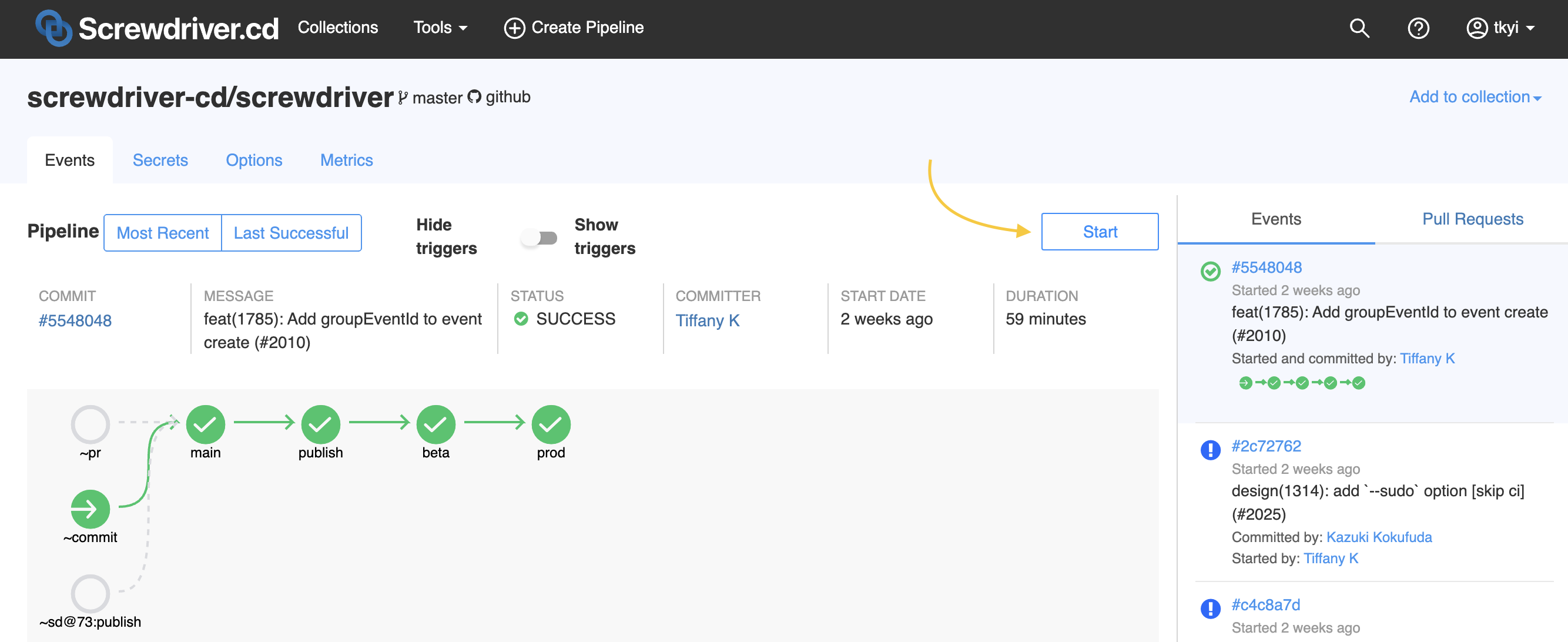
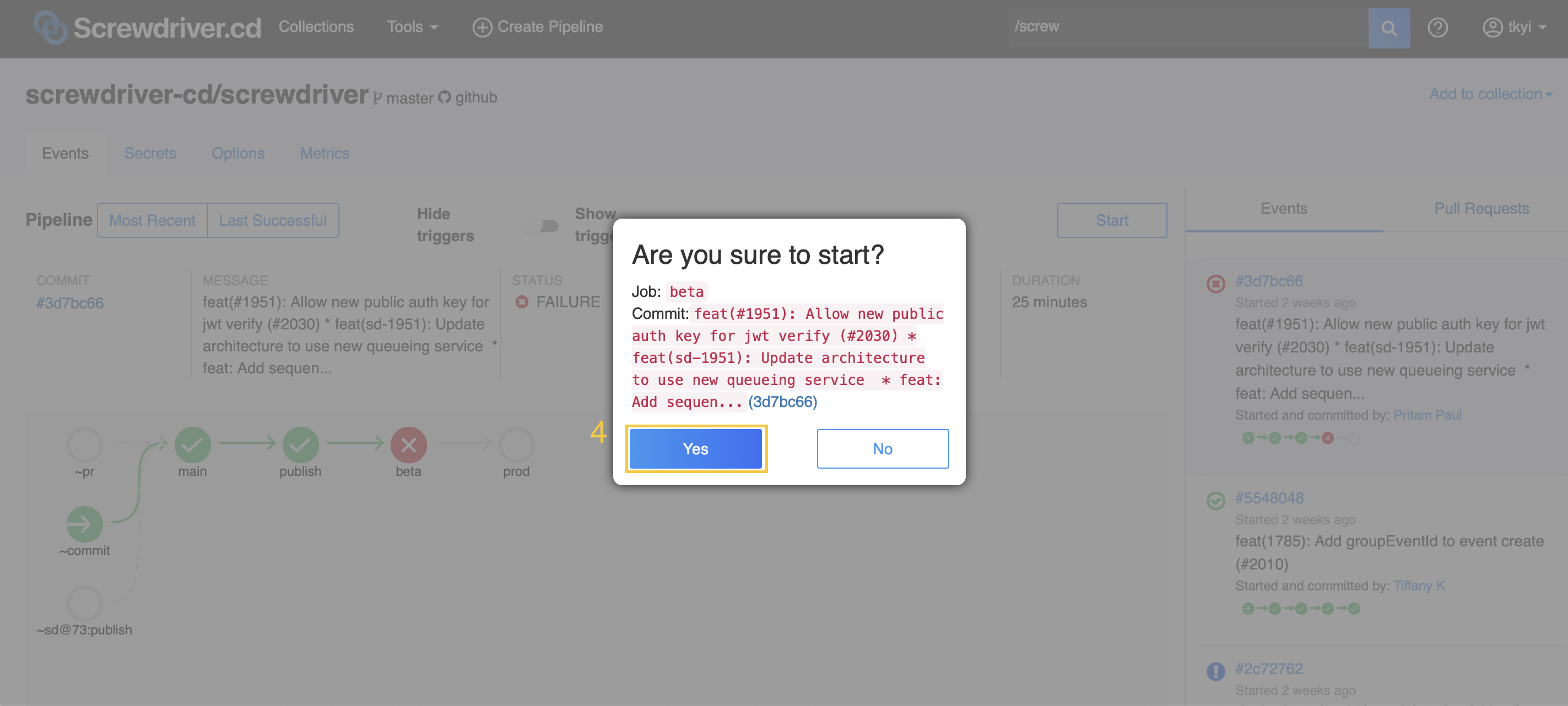
How do I start a pipeline manually?
To start a build manually, you can either click the “Start” button on your pipeline page or click on a build bubble and choose “Start pipeline from here” from the dropdown. Then click “Yes” to confirm. Starting a pipeline using the first option starts all jobs with ~commit event trigger.
Clicking the start button:
See How do I rerun a build? section for the second option.
How do I update a pipeline repo and branch?
If you want to update your pipeline repo and branch, modify the checkout URL in the Options tab on your pipeline page and click Update.
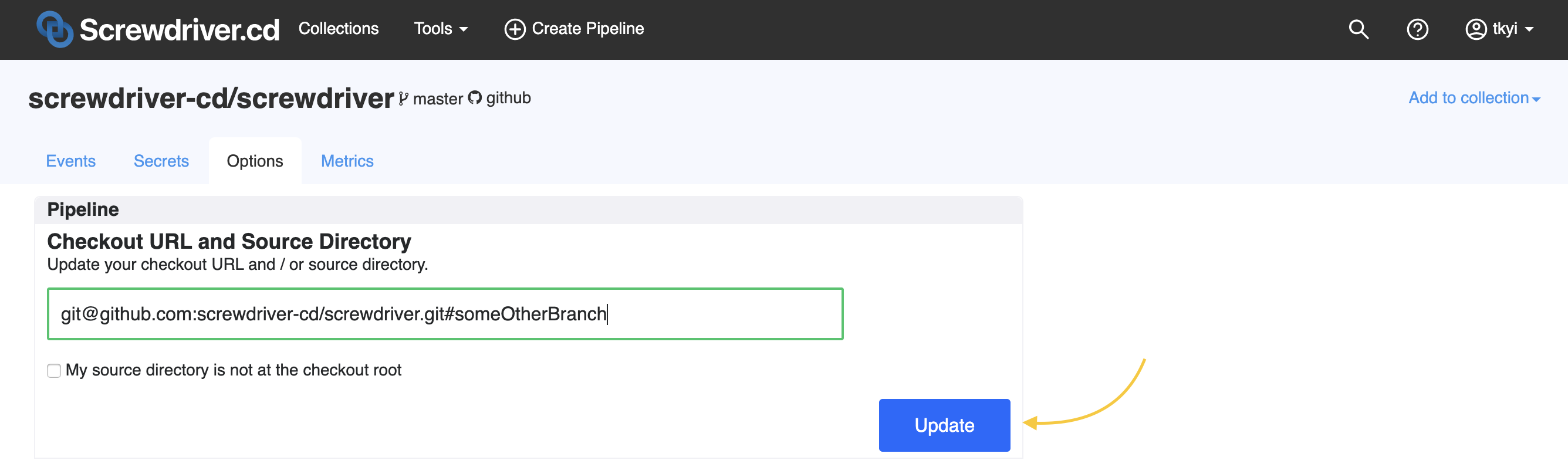
If you transferred or renamed your repo, you can simply Sync your pipeline and refresh the page.
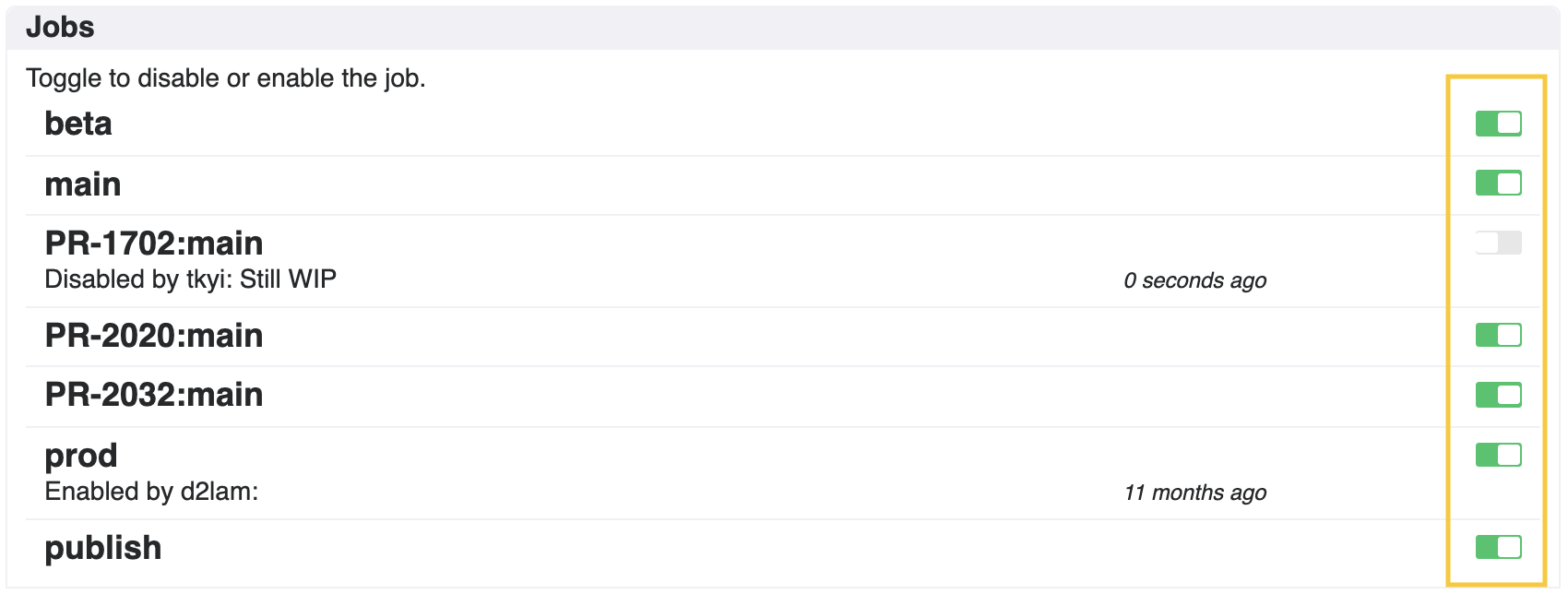
How do I disable/enable a job temporarily?
To temporarily disable/enable a job to quickly stop the line, toggle the switch to disable/enable for a particular job under the Options tab on your pipeline page. You can also optionally provide a reason for disabling/enabling the job.
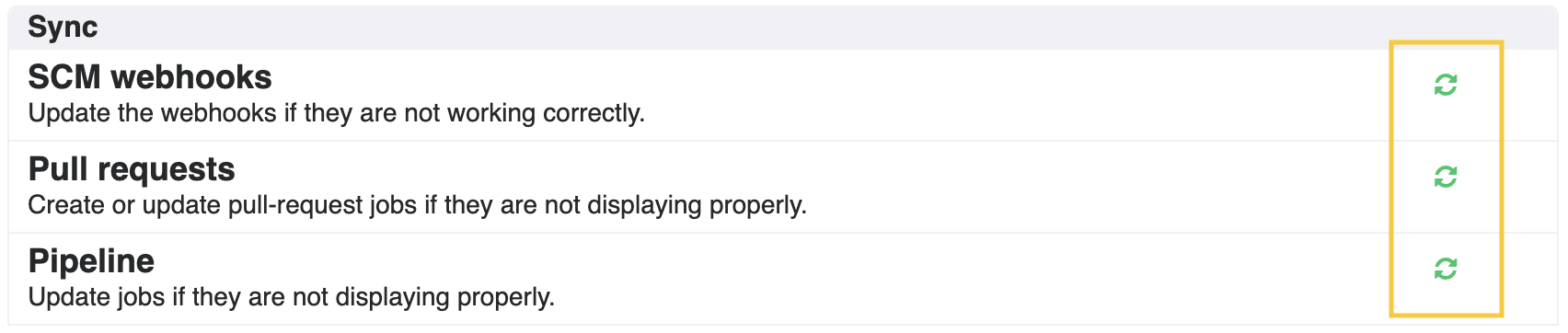
How do I make sure my code is in sync with my pipeline?
If your pipeline looks out of sync after changes were made to it, to make sure it’s in sync with your source code. On the Options tab in your pipeline page, click the Sync icon to update the out of sync elements. There are separate Sync icons for SCM webhooks, pull request builds, and pipeline jobs.
How do I delete a pipeline permanently?
Individual pipelines may be removed by clicking the Delete icon on the Options tab in your pipeline page. This action is not undoable.

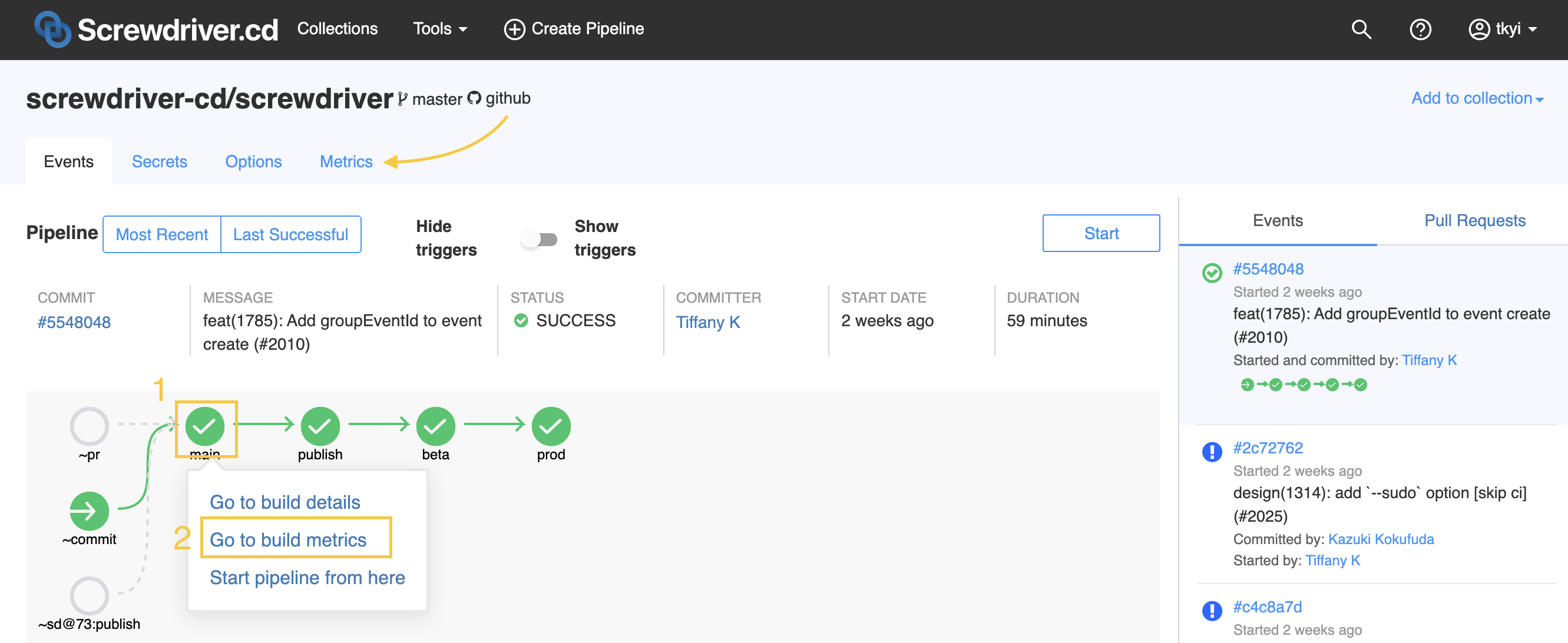
How do I see pipeline metrics?
You can get to the metrics page by either: clicking on a build bubble and selecting “Go to build metrics” or clicking on the “Metrics” tab in the pipeline page.
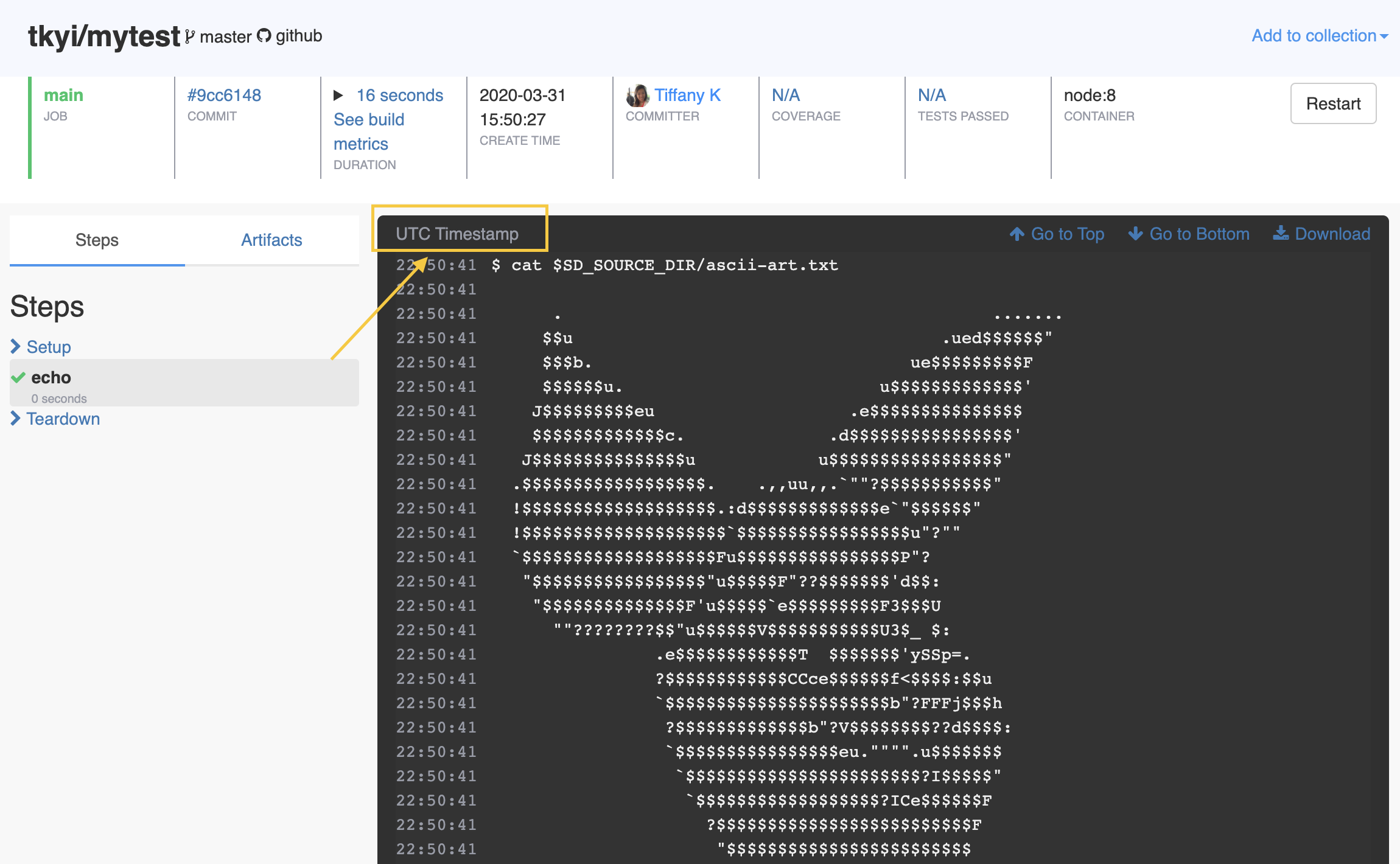
How do I toggle time formats in the build logs?
You can toggle through different time formats for your build logs such as Since build started, Since step started, Local Timestamp, and UTC Timestamp by clicking on the text in the top left corner of the logs.
How do I fix “Build failed to start” error message?
This is caused by a variety of reasons including cluster setup issue like hyperd down (if using executor vm) or a problem with your build image etc. Fixing this issue requires different approaches based on what layer it’s failing.
/opt/sd/launch: not foundThis issue affects Alpine based images because it uses musl instead of glibc. Workaround is to create the following symlinkmkdir /lib64 && ln -s /lib/ld-musl-x86_64.so.1 /lib64/ld-linux-x86-64.so.2when creating your Docker image.- A bug in hyperd sometimes causes images with
VOLUMEdefined to fail to launch consistently in some certain nodes. One of these images isgradle:jdk8. The current workaround is to use other docker images, or to rebuild the gradle image using this Dockerfile but excluding theVOLUMEline.
How do I rollback?
You can use one of two patterns to rollback: either rerunning a build in your pipeline or running a detached pipeline.
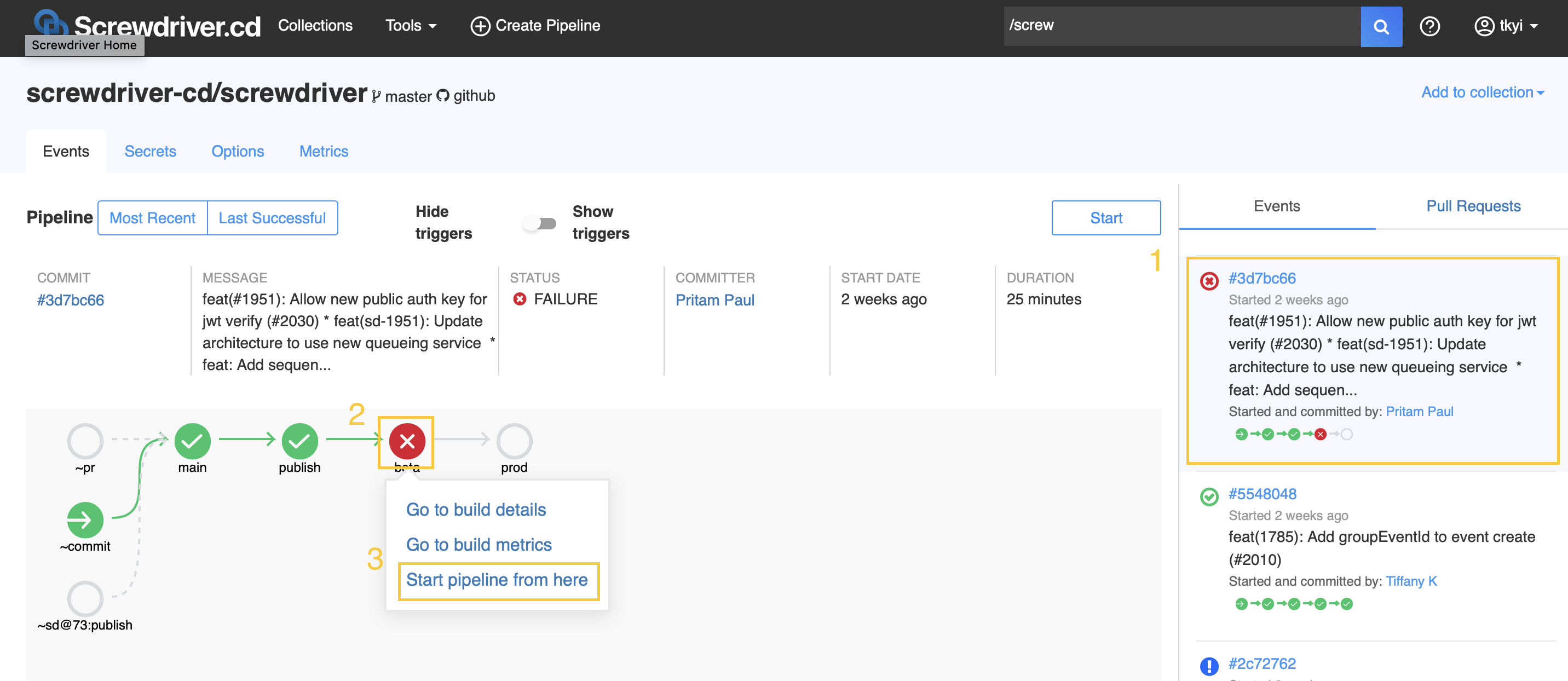
How do I rerun a build or start a detached build?
To rerun a job’s build from a past event, do the following steps.
- Click on the desired event from the event list, which loads the detailed event graph.
- Then, click the job bubble you’d like to rerun.
- In the pop up, click “Start pipeline from here” to rerun that job using that event context.
- Lastly, click “Yes” to confirm.
To rollback, do the following steps on a detached build. You’ll most likely want to use metadata to meta set an image name or version in your last job (in this example, job D) and meta get that name or version in your rollback job (in this example, detached). The detached job will have access to the metadata set in job D.
How do I mark a build as UNSTABLE?
You can update a build with an UNSTABLE status by calling the API in a build. Screwdriver will consider builds marked with this status as not successful and will not proceed with the next job. You can clone our example unstable build repository here.
What shell does Screwdriver use?
By default, step commands are evaluated with the Bourne shell (/bin/sh). You can specify a different shell (such as Bash) with the USER_SHELL_BIN environment variable.
How do I speed up time to upload artifacts?
You can set the environment variable SD_ZIP_ARTIFACTS to true which will zip artifacts before uploading, provided your cluster admin has set it up properly.
How do I permalink pipeline jobs and artifacts?
You can follow the following conventions to permalink your jobs and artifacts for your pipelines with given STATUS:
/pipelines/{PIPELINE_ID}/jobs/{JOB_NAME}/latest
/pipelines/{PIPELINE_ID}/jobs/{JOB_NAME}/latest?status={STATUS}
/pipelines/{PIPELINE_ID}/jobs/{JOB_NAME}/artifacts?status={STATUS}
/pipelines/{PIPELINE_ID}/jobs/{JOB_NAME}/artifacts/file-path?status={STATUS}
Examples:
https://cd.screwdriver.cd/pipelines/1/jobs/main/latest
https://cd.screwdriver.cd/pipelines/1/jobs/main/latest?status=SUCCESS
https://cd.screwdriver.cd/pipelines/1/jobs/main/latest?status=FAILURE
https://cd.screwdriver.cd/pipelines/1/jobs/main/artifacts?status=SUCCESS
https://cd.screwdriver.cd/pipelines/1/jobs/main/artifacts/meta.json?status=SUCCESS
How do I disable shallow cloning?
You can set the environment variable GIT_SHALLOW_CLONE to false in order to disable shallow cloning.
By default Screwdriver will shallow clone source repositories to a depth of 50. Screwdriver will also enable the --no-single-branch flag by default.
If shallow cloning is left enabled and you wish to push back to your git repository, your image must contain a git version of 1.9 or later. Alternatively, you may use the version of git bundled with Screwdriver by invoking sd-step exec core/git "GIT COMMAND".
What are the minimum software requirements for a build image?
screwdrivercd/noop-container is an example container which has the minimum requirements.
Screwdriver has no restriction on build container image. However the container should have at the minimum curl && openssh installed. And default user of the container should be either root or have sudo NOPASSWD enabled.
Also, if the image is Alpine-based, an extra workaround is required in the form of the following symlink. mkdir -p /lib64 && ln -s /lib/ld-musl-x86_64.so.1 /lib64/ld-linux-x86-64.so.2
How do I integrate with Saucelabs?
Read about it on our blog post: https://blog.screwdriver.cd/post/161515128762/sauce-labs-testing-with-screwdriver See the example repo: https://github.com/screwdriver-cd-test/saucelabs-example
How do I run my pipeline when commits made from inside a build are pushed to my git repository?
Screwdriver uses sd-buildbot as default git user. So when you do git commits from inside a build, the commit user will be sd-buildbot.
This has implications for webhook processing. In order to prevent headless users from running your pipeline indefinitely, Screwdriver cluster admins can configure Screwdriver webhook processor to ignore commits made by headless users. This is done by setting IGNORE_COMMITS_BY environment variable. Default git user sd-buildbot is usually added to this list.
Users can override this behavior by using a different git user. For example git config --global user.name my-buildbot and git config --global user.email my-buildbot-email. With this, your git commits from a Screwdriver build will be associated with user my-buildbot and will run Screwdriver pipeline without getting ignored by webhook processor.
Why do my pull request builds fail with the error: fatal: refusing to merge unrelated histories in the sd-setup-scm step?
If your pull request branch has more than $GIT_SHALLOW_CLONE_DEPTH commits (default: 50), you may see pull request builds fail with this error. This message indicates that git cannot find a common shared ancestor between your feature branch and the main branch.
To resolve this issue, you could disable or tune the shallow clone settings (see them listed here) for your job, or reduce the number of commits on your feature branch (e.g. rebase and squash).
Why do I get Not Found when I try to start or delete my pipeline?
Screwdriver pipelines have a 1:1 relation to the underlying SCM repository and this is validated by using not only the SCM repository name but also its unique repository ID. The Not Found error occurs when the SCM repository is deleted and re-created under same repository name (delete & re-fork has same effect). This action results in the new SCM repository getting a new ID and hence failing Screwdriver validations.
If your pipeline is in this state, you have a few options:
- Re-create the pipeline and reach out to Screwdriver cluster admins to remove the old pipeline.
- If you want to retain previous Pipeline ID, reach out to Screwdriver Cluster admins to update the database directly. The
pipeline.scmUrifield must be updated with the new SCM repository ID.
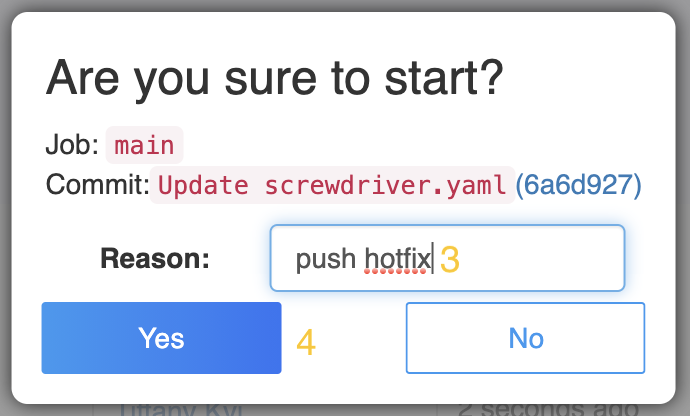
How do I override freeze windows to start a build?
To temporarily override freeze windows to manually start a build, you can use the UI or a commit or API.
In the UI:
- Click on the frozen build bubble.
- Click “Start pipeline from here”.
- Fill in the reason section in the confirmation window.
- Click Yes.

In a commit:
Add [force start] to the commit message of the build you want to start and merge it.
In the API:
Add [force start] to the causeMessage of the build you want to start and use the POST SCREWDRIVER_API/v4/events endpoint to start.
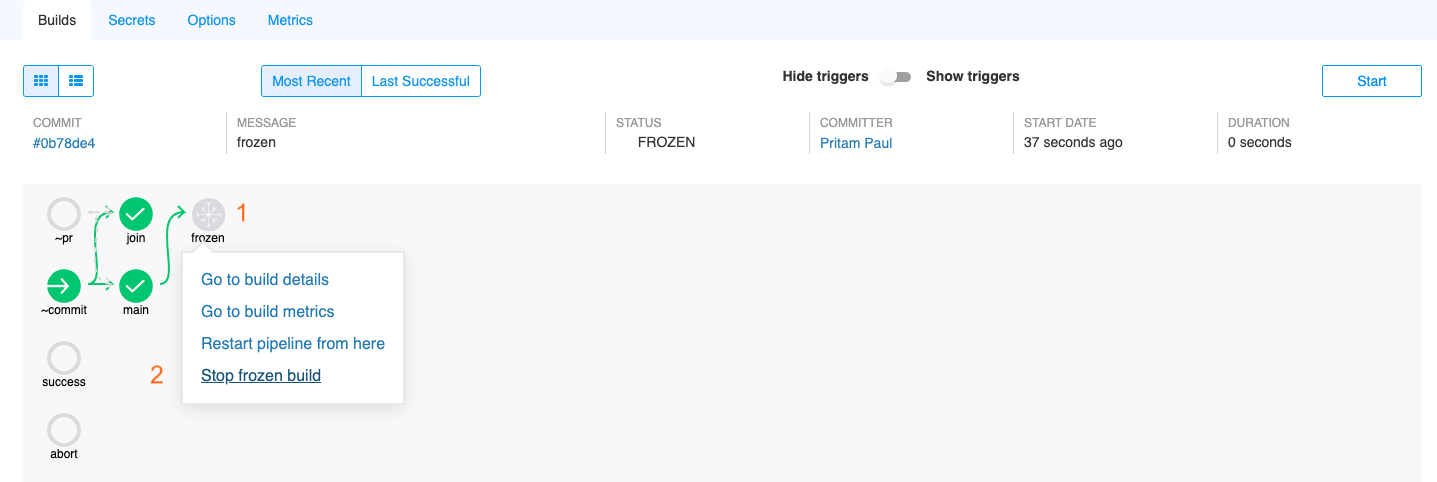
How do I cancel a freeze window and prevent a future scheduled build?
Frozen builds are scheduled to run at the end of freeze windows duration. In some cases users may want to cancel the schedule without changing screwdriver.yaml configuration to prevent a future scheduled build from running. Users can do so by doing the following steps.
In the UI:
- Click on the frozen build bubble.
- Click “Stop frozen build”.
This will set the status for a build from FROZEN to ABORTED and remove the configuration for the future scheduled run.
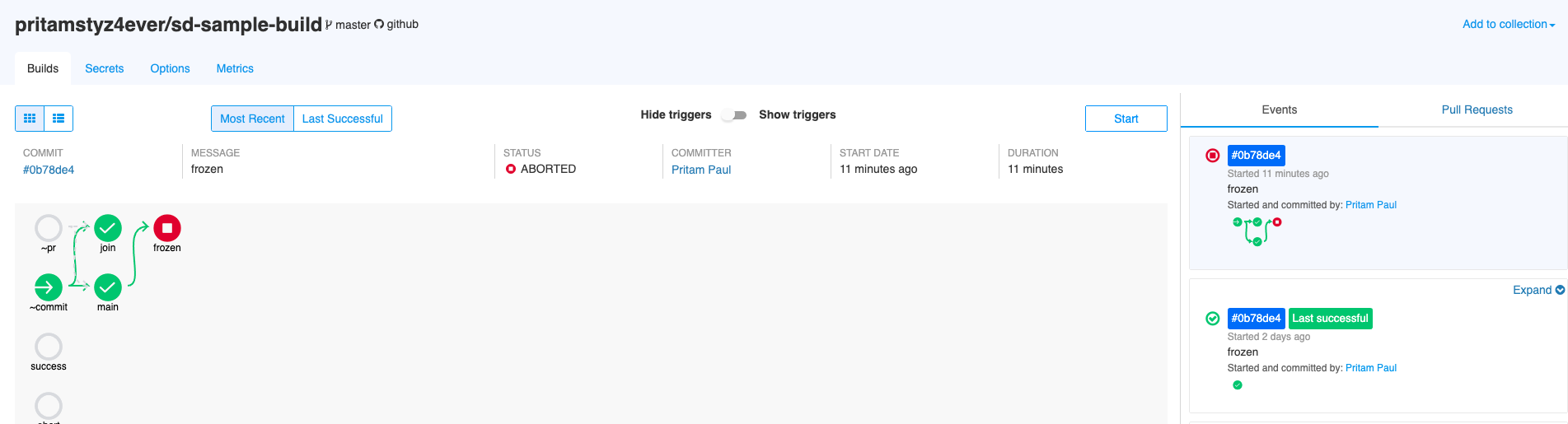
How do I know if my build ran with the latest SCM git sha?
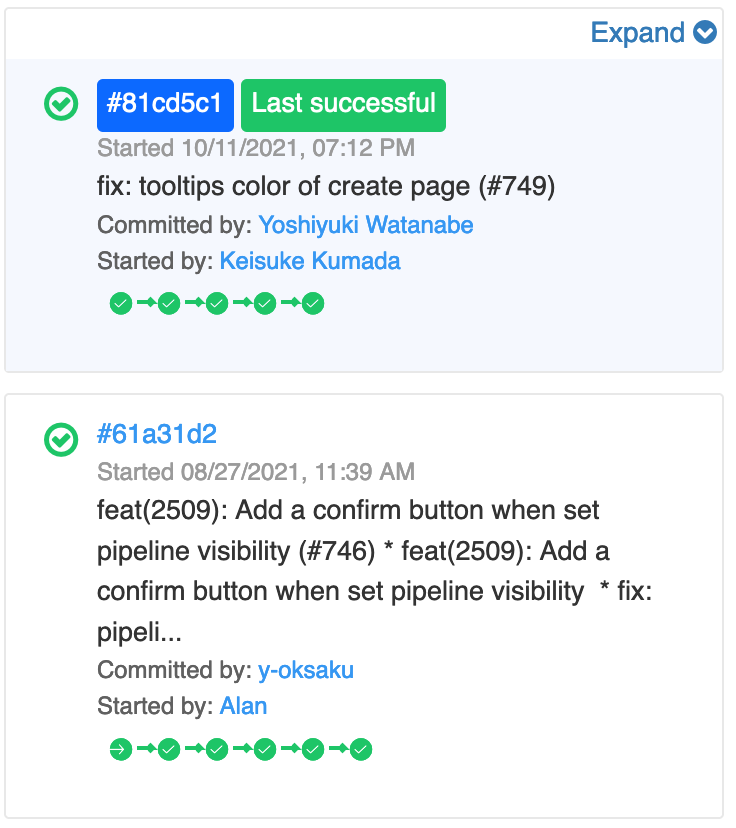
If the build event’s git sha is latest, then Screwdriver UI will display a blue colored background for the sha.
In the following screenshot, the first event has the blue background for git sha because it’s the latest, while the second one doesn’t have any background color.
If you have restarted builds from an older event, then first event will not be the latest. You will have to scroll down to find the latest.
Why do I get Pipeline does not have admin, unable to start job. message?
If a pipeline does not have any active admin, scheduled jobs such as periodic builds will fail. Screwdriver sends this message to Slack/email upon job scheduling failure if Slack/email settings was set for the job.
To resolve this issue, simply sync the pipeline in the Options menu.